My focus at Perficient lately is a fast-moving project with 15+ individuals, complex requirements, and a tight deadline. The experience is extremely valuable. The project is an ETL platform on AWS that uses Lambda for event-driven processing, Elastic MapReduce (EMR) for managed Hadoop clusters, RDS and S3 for persistence, and a handful of other services. Following is a rough diagram of the platform architecture:

My role on the project is to lead the DevOps (i.e. automation) effort. Top takeaways for me:
- Leadership is a fun challenge that requires nurturing talent while staying patient.
- Take time to build your team before trying to build anything else. People and their interactions are everything in a project.
- Racing to the finish line is pointless because you will only encounter issues later on.
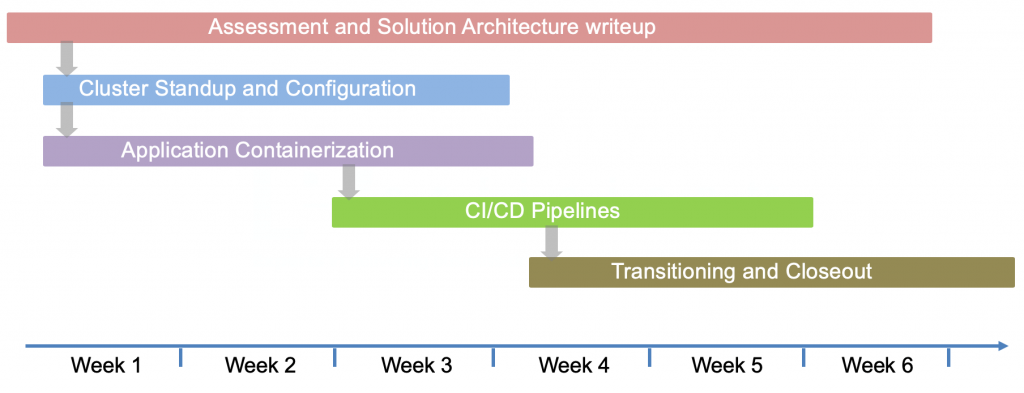
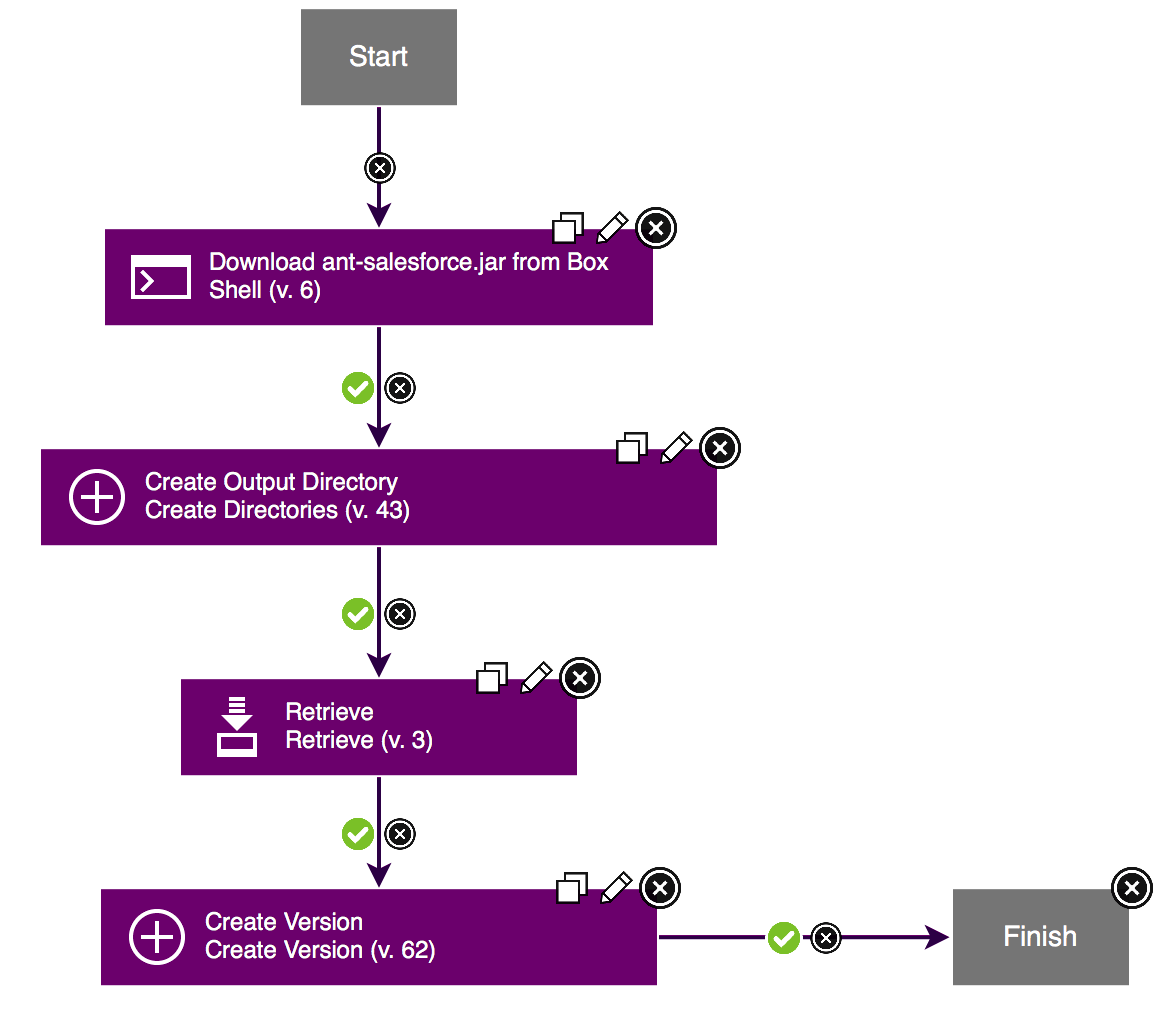
In addition to these lessons, I can share some notes about our automation. We use CloudFormation to facilitate infrastructure as code and Jenkins to drive our pipelines, which includes creation of the CloudFormation (CFN) stacks. Our automation has evolved over six months and is now stabilizing before our first production release, but there remains a lot of opportunity for improvement. Our delivery pipeline is outlined below:

Everything is hosted on AWS including our continuous integration and delivery tools. Our client also has separate AWS accounts for each environment in their promotion path. For development and QA deployments, we can deploy artifacts (code, templates, or scripts) direct from our Git repository. For deployments to staging and production, our release package must be tagged and published to Nexus after a successful QA run, and only artifacts from Nexus can be deployed to those environments.
About Our CloudFormation Templates
Grouping Strategy
No nested CFN stacks, and we’ve separated out related resources into different stacks. Using Jenkins to drive stack creation allowed us to keep things simple in this way. Five IAM templates (roles and policies) as an example for all the different things which need IAM: Lambda, S3 replication, our two EMR clusters, and a Tableau cluster. S3 buckets and their bucket policies in the same templates. All our security groups and rules in one unruly template, though this should probably be split by now. There are no hard and fast rules here but AWS does provide some good advice.
Naming Conventions
We use a lot of Fn::ImportValue statements in our CFN and we assume that resources/outputs will always be named correctly. As far as resources, this is a safe assumption except when manual processes occur. Regardless, instead of passing stack names into templates as parameters (as AWS docs demonstrate), we pass a number of other common parameters (3-4) and use a Fn::Join statement to build the CFN Export names:
{"Fn::ImportValue": {"Fn::Join": ["-",
[{"Ref": "ApplicationID"},{"Ref": "Environment"},{"Ref": "BundleName"},"code-bucket-id"]
]}}
We actually don’t vary two of the parameters at all so these statements could be dramatically simplified at this point.
Layered Infrastructure
CFN is excellent about not allowing you to delete stacks which are referenced by another stack. This ultimately leads to layers of dependencies between your templates. For example, IAM and VPC resources, as well as SSM Parameter Store keys and some initial buckets must be created first. Next, you can deploy Lambda functions and a RDS instance, etc. You cannot delete your security groups though without also deleting the RDS stack (a no-no for us), and so on. For the most part, the stack dependencies are not a problem. CFN can update security groups and policies quite smoothly, in fact. The rigidity is a bit awkward though since there’s less immutability without deleting and recreating the whole set of stacks.
The following table outlines the layers of our infrastructure:

Change Control
Without complete immutability, drift has been a problem for us particularly in our development account where changes are less-controlled. Application updates or testing will often require quick updates to security groups or IAM policies in the AWS web console, which CFN is oblivious to and doesn’t magically carry forward. As the team learns how to communicate more effectively though, drift becomes less of a problem.
IAM Managed Policies
We spent a lot of energy working towards a set of IAM managed policies which were least permissive as possible. Our common parameters and naming conventions came in very handy with respect to limiting resources in a policy statement. For example:

We avoided inline policies altogether.
S3 Bucket Policies
We need to restrict bucket access to specific IAM roles within the same AWS account, and so we implemented this approach. This is effective, but introduces an additional template parameter for each role/user in the Deny statements. Fortunately, Jenkins handles this for us by fetching the parameter value using the AWS CLI and passing that to the subsequent create-stack command:
aws iam get-role --role-name $roleName --query 'Role.{RoleId:RoleId}' --output text
Lastly, all of our CFN templates were authored from scratch using a skeletal template (with just our common parameters) as the basis for new ones.
Regarding Our Jenkins Pipelines
Pipelines in SCM
We use pipeline scripts in SCM exclusively. The basic flow for most stages is: (1) setup parameters for CFN template, (2) create CFN stack using template, (3) wait for stack to complete. Other stages include our Maven build, Git tag, publish to Nexus, upload to S3, one that loops through aws s3api put-bucket-replication for our buckets, preparation, and more.
Pipeline Framework
Our client internally develops a “reference pipeline” which is a framework for structuring Jenkins automation, defining job flows, leveraging Nexus for artifact promotion, and fetching inputs from a central file. Overall, the framework minimizes risk of human error during job setup or invocation, and ensures that a solid release process is followed through all environments. A “seed” job first scans the source repo and creates a new folder in Jenkins (or updates an existing one) for the source branch. Within this folder tied to the branch are subfolders for each target environment, and within each subfolder are instantiations of the pipelines. The Development folder includes the job for tagging the code and the QA folder includes the job for publishing to Nexus. The deployment pipelines for Staging and Production are configured to deploy from Nexus.
Following is the folder structure for our Jenkins automation. Notice how pipeline stages are actually split into separate files. ./jobdsl/jobs contains the files which define our pipelines and the sequence of stages:

Check Before CFN Create
Early on with CloudFormation, I looked for a command that would update the stack if there were updates to make, otherwise just move on. Either aws cloudformation deploy was recently updated to include –no-fail-on-empty-changeset or I simply didn’t notice this till now. In any case, we currently we do not support CFN stack updates in our pipelines. Instead, we check for stack existence first (by assuming a strict naming convention) and only if null do we run aws cloudformation create-stack. This has proven pretty handy though I would like to support CFN stack updates in some cases.
Continuous Lambda Updates
With the “check before create” approach just discussed, we included a stage at the end of one of our pipelines which invoked aws lambda update-function-code for each of our Lambdas. This allows us to use the same pipeline for deploying initial code/infrastructure and deploying simple updates:

Keep It Simple
We try to keep things simple. We use a set of shared libraries for common functions (create CFN stack, upload to S3 with KMS, bind parameters to template) and when we need something else, we use vanilla AWS CLI commands. We also keep our plugin requirements to a minimum.
CloudFormation is a powerful way to define all of your AWS infrastructure. For the ETL platform on this project, we have about 20 templates. Running these individually in the AWS console is slow and error-prone. Using Jenkins in combination with CFN allows us to speed up our deployments, lower risk, and execute complex pipelines for seamless automaton. For more details about this project, please get in touch!